

El auge del Internet de las Cosas (IoT) ha impulsado el desarrollo y reducido los costos en tecnología y comunicaciones, junto con importantes avances en software de análisis de datos, como el procesamiento de Big Data y datos en tiempo real. Esto ha posibilitado tomar decisiones informadas de manera instantánea y ha dado lugar a la creación de distintas arquitecturas destinadas a gestionar y procesar el enorme volumen de datos generados por los dispositivos conectados. Los tres enfoques clave para el procesamiento de datos en este ámbito son el ‘edge computing’, el ‘fog computing’ y el ‘cloud computing’, cada uno diseñado para satisfacer diferentes necesidades de latencia y almacenamiento.
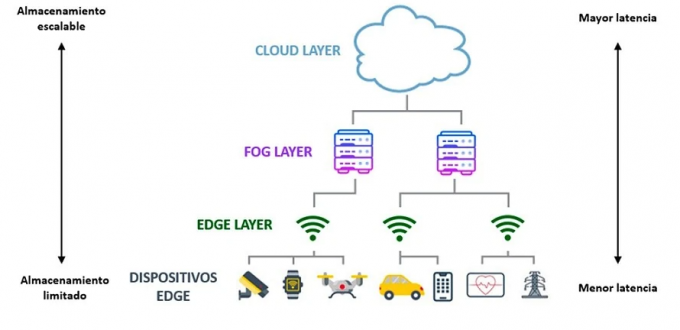
Como se muestra en la figura 1, el ‘edge computing’ se centra en procesar los datos cerca de su origen, en el ‘borde’ de la red, sin la necesidad de enviar los datos a un servidor central. Esto reduce la latencia y permite respuestas rápidas, lo que es esencial para aplicaciones en tiempo real como el IoT y sistemas industriales. Sin embargo, puede tener limitaciones en cuanto a capacidad de procesamiento y almacenamiento en comparación con el cloud computing, que proporciona acceso a recursos escalables y almacenamiento a través de Internet desde centros de datos remotos.
Por otro lado, el ‘fog computing’ emerge como un modelo intermedio entre el ‘edge’ y el ‘cloud computing’, ubicándose generalmente a medio camino entre el lugar donde se generan los datos y los centros de datos en la nube [1]. Este paradigma amplía las capacidades del ‘edge computing’ al distribuir el procesamiento, almacenamiento y aplicaciones más cerca de los dispositivos finales, pero aún dentro de la red. El ‘fog computing’ proporciona mayor flexibilidad y eficiencia al repartir la carga de trabajo entre los dispositivos ‘edge’ y los centros de datos en la nube [2]. Esta arquitectura es útil en situaciones que requieren una combinación de baja latencia, procesamiento local y la capacidad de aprovechar recursos escalables en la nube, sin depender completamente de ella.
El ‘cloud computing’ proporciona servicios como servidores, almacenamiento y bases de datos a través de Internet. Su principal ventaja es la capacidad de ofrecer recursos casi ilimitados bajo demanda, lo que permite a las empresas escalar sus operaciones sin grandes inversiones en infraestructura física. Sin embargo, puede tener una mayor latencia, ya que los datos deben viajar hasta centros de datos remotos para su procesamiento. Este modelo es más adecuado para aplicaciones que no requieren respuestas en tiempo real o que gestionan grandes volúmenes de datos a largo plazo.
En estos sistemas de procesamiento distribuidos, la latencia y escalabilidad varían notablemente entre las tres capas. Los dispositivos ‘edge’, situados cerca del origen de los datos, tienen latencias de milisegundos. Los servidores ‘fog’, ubicados en centros de datos locales, presentan una latencia moderada adecuada para muchas aplicaciones. En contraste, la nube, con servidores distribuidos globalmente, puede experimentar mayores retrasos, especialmente si los datos deben recorrer largas distancias, como entre continentes o países distantes.
Noticia completa: Interempresas

